
“Voordat we beginnen met een nieuw project moeten we zeker stellen dat de beschikbare data klopt en compleet is”. Met die dooddoener wordt menig logistiek analyseproject uitgesteld. Het klinkt zo logisch, maar is het terecht?
Logistieke processen genereren data. Vrijwel iedere stap in de doorloop van een logistiek proces levert op z’n minst een tijdsregistratie (timestamp) op. Deze registraties zijn grotendeels bedoeld om de volgende stap in het proces te starten. Daarna verliest de registratie vaak zijn primaire waarde.
Toch kan deze data ons nog veel vertellen over het verloop van processen in de praktijk. Analyse van procesdata biedt onverwacht inzicht in knelpunten of verbeterkansen. We noemen dit “Data Discovery”, om de werkwijze te onderscheiden van traditionele “Business Intelligence”.
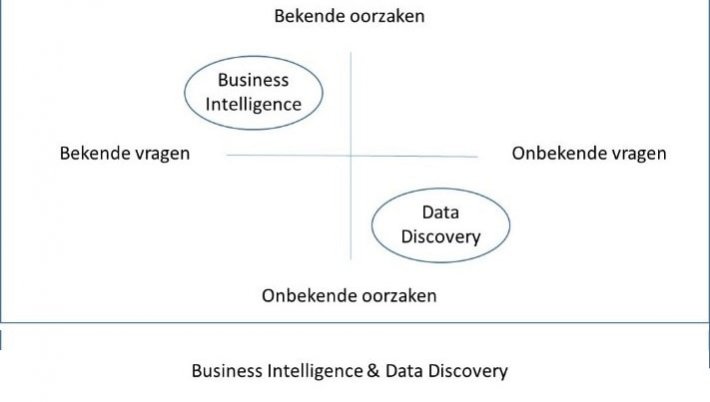
Business Intelligence geeft antwoorden op vragen: bijvoorbeeld “wat is de gerealiseerde leverbetrouwbaarheid?"
Data Discovery faciliteert een zoektocht, met focus op een probleemveld, maar nog zonder een vastomlijnde vraag of hypothese. Een voorbeeld hiervan is een data-analyse naar de verbeterkansen van leverbetrouwbaarheid.
Bij die zoektocht experimenteren we met de “dimensies” die in de database aanwezig zijn. Met dimensies bedoelen we de kolommen in de datamatrix. Bijvoorbeeld: Toon de leverbetrouwbaarheid per regio, of per klant, per productgewicht, per tijdvak, per weekdag etc. We weten dan nog niet waar we naar zoeken, maar proberen verbanden te vinden die niet eerder onderkend waren.
Veel IT projecten schieten tekort omdat de betrokkenheid van de proceseigenaar onvoldoende is. Praktische proceskennis is onontbeerlijk om de getoonde informatie op bruikbaarheid en informatiewaarde te beoordelen. Op die manier komen verrassende conclusies met mogelijke maatregelen boven water.
Ook zien wij dat veel logistieke BI projecten uitgesteld worden omdat de datakwaliteit ter discussie gesteld wordt. Moet de datakwaliteit perfect zijn voordat we met zo’n procesanalyse kunnen beginnen? NEE! Het lukt toch niet om de dataset tevoren helemaal “schoon” te krijgen, juist tijdens de analyse komen we nog onverwachte vervuiling tegen. Dit wordt vaak vanzelf zichtbaar. We kunnen die vervuiling dan alsnog uitfilteren of negeren bij onze interpretatie.
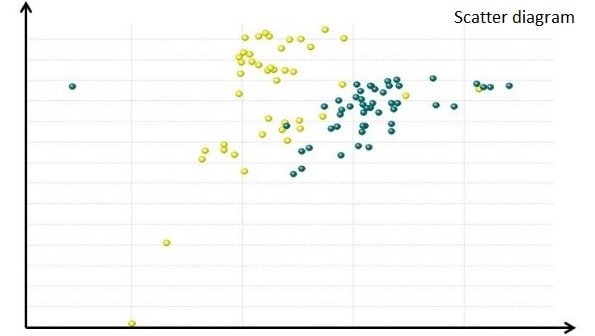
Probeer maar eens een dataset in een scatterdiagram te presenteren, waarbij de kleuren van de punten een specifieke waarde in een dataveld vertegenwoordigen. De verbanden tonen zich dan als gekleurde puntenwolken, terwijl de vervuilde data als verdwaalde kometen aan de randen van het diagram verschijnen.
Data Discovery is net als het leggen van een grote puzzel. Je moet gewoon beginnen. Je hoeft niet eerst te controleren of alle 1000 stukjes er nog zijn. Dat telresultaat is niet relevant. Stel dat je 1002 stukjes telt, weerhoudt dat van het leggen van de puzzel? Als je een puzzel van een berglandschap gaat leggen, dan begin je met de horizon, en niet met de blauwe lucht. Hoe doe je dat? Het begint met sorteren op kleuren en patronen. Daarna leg je de rand en de sprekende delen van de afbeelding. Daardoor wordt het grote geheel al duidelijk voordat de puzzel af is.
Met behulp van goede Data Discovery software is het combineren, sorteren en selecteren van data een kleine moeite, waarna het leuke werk -het leggen van de puzzelplaatjes- kan beginnen.
Bij Districon hebben we goede ervaringen met het gebruiken van grote, onbewerkte logistieke datasets. Bij de start van de analysefase maken we ons nog niet al te druk over de compleetheid en de datakwaliteit. Tijdens de analyse ontstaat daarover duidelijkheid en nemen we maatregelen. We gaan liever op zoek naar de informatieschat die in de data verscholen is, dan ons kruit te verschieten aan perfecte datavelden waar we later toch geen gebruik van maken.
Ons advies:
- Richt je op de beschikbare data en begin daar waarde mee te creëren.
- Betrek de proceseigenaar bij de analyse. Uit de dialoog ontstaat inzicht en begrip.
Dat is vaak voldoende voor logistieke analyse en het nemen van het juiste besluit. Goede data verzamelen is nooit een doel op zichzelf; goede besluiten mogelijk maken, daar gaat het om.